
Today we discuss origins of Abaqus ODB data, how these origins affect file size and database performance, and methods to improve both.
For large or complex models, some users may find that their simulation results files occupy significant disk space and take longer than desired to load and interact with in Abaqus Viewer. This article will provide insight into the causes and solutions to such issues.
Where does the results data in an Abaqus ODB file come from?
With linear simulations it is relatively straightforward to request only the results that you need, resulting in predictable results file sizes and performance. However, with non-linear simulations, it is difficult to know what output data you should request before running. Often users request more than is needed because if they are missing some output, they must rerun the entire simulation to get the new output.
Don’t miss the eSeminar on July 28th. Register now!
There are three ways results data can increase in size for a given analysis.
- The first is by having more model features. With additional features comes additional complexity. This may mean more instances, additional constraints, finer mesh, etc.
- The second is through requesting more output frames such that the same output requests are repeated for more time points in the simulation.
- The final method is by requesting additional outputs, such as adding output data for damage criteria, plastic strains, contact opening distance, etc. essentially having more fields/history outputs for the same number of time points.
Another cause of increased data can be multiple configurations/conditions for a given model (including DoE/optimization), but since those results are typically stored in a separate file, it will be ignored here.
What does having a larger output database affect?
Model complexity
If the model grows in complexity (such as having a larger mesh), the initial load time will increase as Abaqus must load the model data before displaying to the user. Interactive requests such as generating XY Data, selecting regions of the model in the viewport, changing the view (rotate/pan/zoom), creating new field outputs or getting data from paths will take longer with increased model complexity as the code must consider more features (elements, part instances, etc.) any time such an operation takes place.
Number of output fields
When a user requests more output fields, storage space of the database will increase, however Abaqus loads the actual result field (stress, displacement, etc.) on-demand. For instance, it will not load stress data in any frame until it has to. This reduces memory consumption and ensures we are not spending time loading unnecessary data.
Number of time points
Increasing the number of time points (ex. asking for output every 0.1s instead of every 1s) for the output requests will not significantly affect the initial load time, but will cause operations that require loading all frames (such as animations) to take longer on the first pass.
What workflows do large ODBs affect?
With large models slowing down the user-interface, the first and foremost person affected is the primary ODB consumer, usually the person that ran the model. Larger models will slow down the post-processing interface, making it take longer for the GUI to determine what the user is clicking, what should be highlighted, etc.
If the database has to be passed over a network, say from an HPC to another storage area such as the user’s local computer, the time it takes to transfer the database to the second system will increase linearly with the model size.
How do we keep our results data small and agile?
There are various methods to help keep results databases from taking over the computer’s hard drive and to help the GUI to keep the speed up. I will detail some suggestions below.
- Request more precise output (if possible). Separate field outputs to those that are critical to have during the run and those which you just want to see at the end of a step/analysis. Request these outputs at different frequencies.
- Request output averaged at nodes instead of at their integration points. If outputs such as stress and strain are stored in the ODB as averaged at nodes, Viewer will not have to do the extrapolation and averaging before displaying the results, thus boosting your frame load performance and reducing time to view a particular result. It also decreases the results size on disk. The downside is that you no longer have the integration point data, so some results such as the mises stress value for plastic materials may not exactly line up with the material definition due to extrapolation.
- Trigger output frames when certain conditions are met
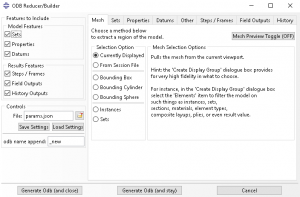
- Use the ODB Reducer/Builder (ORB) plug-in now built-in to Abaqus. The standalone version is available here on the Simulia Community
ODB Reducer/Builder (ORB)
The ODB Reducer/Builder (also known as the OEBT/ORB) is a tool developed to create reduced data ODBs from an original odb. It can create a new database from either a selected model region or the whole model and can carve out field data with a high degree of fidelity. For instance, one could create a new odb from the region of the model currently displayed in the Abaqus CAE viewport, or from only the elements with a stress value over 200MPa. This new database could contain S, LE for Step-1 frame 5, and COPEN, S, LE, PEEQ for Step-2 frames 12 and 15 from the original output of S, LE, PEEQ, COPEN, etc. for all frames. It also allows you to select which specific model features to carry over, thus allowing you to remove unneeded sets or datums. Additionally you can completely remove materials, sections and beam profiles or revert them to default values which can be good for data security. The ORB can run in interactive mode, or through noGUI for those that have a set routine or many databases to generate reduced datasets for. With all of these features, the ORB enables the user to create the most reduced dataset possible, allowing for faster load and interaction time in CAE as well as smaller size on disk.
Don’t miss the July 28th eSeminar on this topic: Maintaining Agile Results Data in Abaqus
SIMULIA offers an advanced simulation product portfolio, including Abaqus, Isight, fe-safe, Tosca, Simpoe-Mold, SIMPACK, CST Studio Suite, XFlow, PowerFLOW and more. The SIMULIA Community is the place to find the latest resources for SIMULIA software and to collaborate with other users. The key that unlocks the door of innovative thinking and knowledge building, the SIMULIA Community provides you with the tools you need to expand your knowledge, whenever and wherever.

Katie is the Editor of the SIMULIA blog, an expert in engineering and scientific communication, and a strategic digital marketer. Katie has a BA in English and Writing from the University of Rhode Island and a MS in Technical Communication from Northeastern University. She is also a proud SIMULIA advocate, passionate about democratizing simulation for all audiences. Katie is a native Rhode Islander who lives just outside of her favorite city, Providence. She is a true New Englander and loves sharing all the cool things NE has to offer. She enjoys a variety of hobbies including history, astronomy, science/technology, science fiction, true crime, fashion and anything associated with nature and the outdoors. She is also mom to a 6-year old budding engineer and two crazy rescue pups.