
Introduction
A surge of inflation is sweeping through the country of Chemistry. Consequently, chemists are finding themselves compelled to shift their perspective from focusing solely on individual compounds to considering libraries of compounds as the new norm. Libraries have become the “folding money” of that country, while carrying around a pocketful of loose change is just getting more and more annoying.
If you want to count your stash, then it is good to have a tool built for the job. BIOVIA Pipeline Pilot [1] is just such a tool. It excels in the multitude of tasks around library design, including R-group analysis, enumeration, diversity assessment, toxicity assessment, and so on.
This was made clear to me when I discovered [2], an informative paper by scientists at GSK, who are directly confronting the increasingly quick HTS turnaround times, and edging closer and closer to a completely automated process. One way they did this was to design a combinatorial library (the “MMP-12” library, named after the target protein). In the Supplementary Information, they have kindly provided the (2500) structures and some results.
Suppose I was a cheminformatician wanting to explore this library. Assume I wanted answers to the following simple questions?
- Could I find the reagents used to create this library (it is a 2-step synthesis)?
- Could I assess the TOX profile of these reagents, or the library itself?
- Could I get sourcing information for the reagents?
- Could I assess the diversity of the library, and compare it to others?
With the capabilities of Pipeline Pilot, you can demonstrate that it is a matter of a few hours to knock together protocols that answer these questions. Most of the fast pace of development is thanks to a large number of mature components and example protocols in the Pipeline Pilot Chemistry Collection [3]. We give a quick overview of their use on the MMP-12 library below.
Reagent Analysis
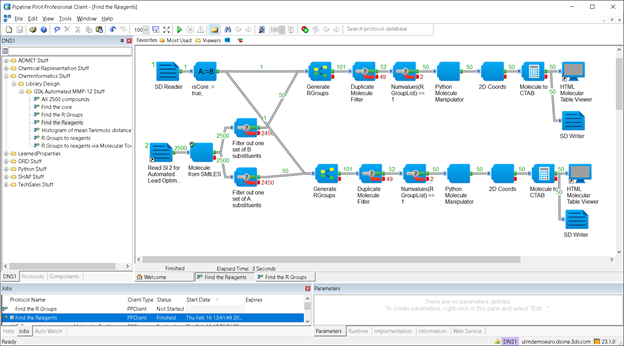
There are several steps in this:
- Finding the MCSS (Maximum Common Substructure), or core. There is a component precisely for this; the only critical detail here is that it is a 2-step synthesis, so you need to set the MinimumSubgraphSize parameter carefully.
- Finding the R-groups on both substituent sites. This is done by the (two) Generate R Groups components shown above.
- Transforming the R-groups into reagents. There are leaving groups in the reactions, and they need to be added back. For this, I found it quickest to pick up my “Molecular Toolkit” component, in its Python costume.
The results can be double-checked against the depictions of the reagents, from the Supporting Information for [2].
Sourcing Information
Once the reagents were in hand, a VERY simple (4-components) protocol allowed me to ask the Internet where I should buy these from, what sizes are available, and so on.
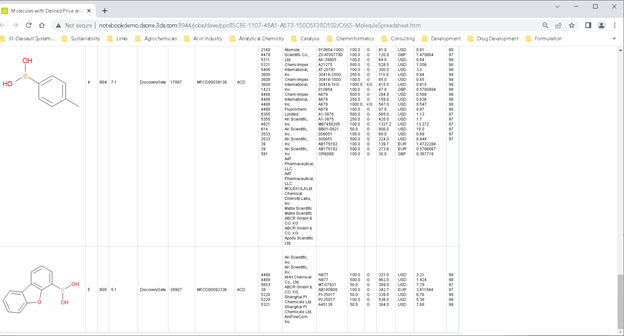
Here I was able to specify my favorite suppliers, minimum container sizes, and a few other things. With a bit more work, you could even do cross-supplier analytics.
Diversity and Tox Assessments
We will just focus on the second of these. The first follows the rather nice “Mean Tanimoto Distance” method described in [4], where the MMP-12 library was analyzed and compared with several others as part of a novel “Coverage Score” subsetting algorithm.
Using a similar approach, we show below in Figure 3 the comparison of the distribution of Ames Mutagenicity for the A- and B-reagents, also compared with a subset of the NCI drugs:
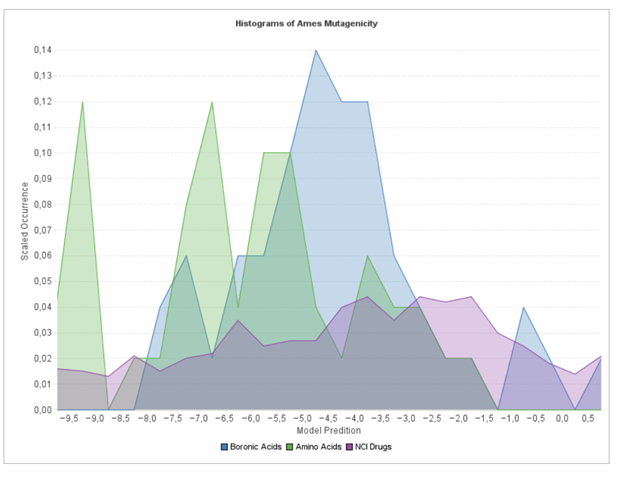
I won’t show the protocol in this case, but it is straightforward to believe that there are “out-of-the-box” components for calculating the Ames Mutagenicity, assembling the distribution, and displaying it for multiple sources of compounds. The protocol took about an hour to put together and confirms an Internet rumor that the boronic acids may be of concern.
Conclusion
Medicinal chemistry teams have to increasingly be capable of analyzing and comparing large numbers of libraries for purchase but also to possibly synthesize internally. They need capable, simple-to-use tools which can deliver these analyses quickly. In this realm, BIOVIA Pipeline Pilot stands unparalleled, excelling in precisely this task.
References
[1] https://www.3ds.com/products-services/biovia/products/data-science/pipeline-pilot/
[2] https://pubs.acs.org/doi/pdf/10.1021/ml100191f
[4] https://pubs.acs.org/action/showCitFormats?doi=10.1021/acs.jcim.2c00258&ref=pdf

Principal Scientist at Dassault Systemes BIOVIA working to ensure the success of both BIOVIA and its customers whose main focus is software to support the process of efficient experimentation, and management of the knowledge which this generates. A secondary focus is integration - pulling together software, data and people into novel situations which generate value.