
Introduction
BIOVIA Pipeline Pilot has democratized access to cutting-edge analysis methods and scientific data-driven and AI-based workflows. By providing a simple, clean, and easy-to-use interface that does not rely on users programming expertise, scientists and users at all stages of their careers can effectively use the data at their disposal.
I joined BIOVIA earlier this year and enjoyed learning how to use Pipeline Pilot during my onboarding training. Part of the power of Pipeline Pilot comes from the myriad components and protocols available in the different collections. These provide a vast range of capabilities, and are accompanied by detailed documentation and guides to ensure they are used effectively.
One thing I found myself doing was turning to my colleagues to ask questions about which components and protocols I should use for accomplishing specific tasks. While Pipeline Pilot and the help documentation have powerful search capabilities, it was often quicker to ask the person next to me how to achieve a particular goal. This got me thinking – wouldn’t it be nice to have an on-demand Pipeline Pilot expert for everyone, not just people like me who are lucky enough to sit next to the developers?
In this article, I will cover some of the internal prototyping we are doing at BIOVIA to give users access to a large language model (LLM) that can provide this kind of on-demand expert assistance. I will also share some of the exciting ideas we have for how this could lead to a fully-fledged agentic LLM capable of designing and running Pipeline Pilot protocols to assist users in their work.
Large Language Models
Since the release of ChatGPT in November of 2022, it is safe to say that large language models (LLMs) have entered the public consciousness. These systems leverage highly scalable neural network architectures and vast datasets to perform a wide range of tasks that take advantage of their natural language processing capabilities.
Despite their incredible potential and promise for various domains, LLMs are not without their quirks. When an LLM is asked a factual question, one possible outcome is a convincing and plausible sounding stream of false, misleading, contradictory or nonsensical information, which is commonly referred to as a hallucination. Several causes of hallucinations have been hypothesised, such as incomplete, poor-quality or contradictory examples in the model training data, the probabilistic nature of the LLM itself and other issues related to the architecture and deployment of the LLM.
Regardless of the cause, the problem of hallucination seems to preclude the ability of companies and users to leverage LLMs to provide reliable insights about their own data. However, several approaches are available to mitigate against this issue.
One option is to fine-tune the LLM on the dataset of interest. Fine-tuning a model effectively continues the training process of the LLM on the new data, updating the model parameters such that it is better equipped to generate answers about that particular domain. This is very effective for increasing the specialised knowledge of the LLM about the domain of the new dataset, as well as guiding its behaviour and the types of answers it will provide. However, fine-tuning comes with several disadvantages:
- It can cause the LLM to forget some of what it learned before fine-tuning
- It is reliant on high-quality training data, which can be expensive to collect
- It is relatively slow and computationally expensive
- Updating the knowledge in the fine-tuned model requires additional training
An alternative approach, which is computationally cheaper, more flexible and enables much easier updating than fine-tuning is Retrieval Augmented Generation.
Retrieval Augmented Generation
Unlike fine-tuning, which aims to provide the LLM with additional knowledge by modifying the neural network parameters, Retrieval Augmented Generation (RAG) aims to provide the LLM with additional knowledge by providing it in the context of the prompt. This is becoming increasingly attractive as model context lengths (the length of the sequence that the model can process in one go) are growing rapidly; context lengths for state-of-the-art models have grown from ~103 (equivalent to several paragraphs) to ~106 (equivalent to multiple books) in the space of just two years. Increased context lengths allow more information to be given to the LLM together with the user query, increasing the scope of questions they can successfully tackle without fine-tuning.
The main steps involved in RAG are as follows:
- Retrieval: A search is performed over a previously compiled database of documents to find those most relevant to the user query. This can be done with traditional “keyword” type searches, as well as semantic vector-based searches. The most relevant documents are then concatenated with the user query and provided to the LLM.
- (Augmented) Generation: The LLM generates a response to the user query with the relevant documents also in its context window. This allows it to refer to these documents directly during the generation of its response. If the retrieved documents are sufficiently relevant to the query, this reduces the likelihood of hallucination and increases the accuracy of the response.
The use of RAG therefore ensures that the LLM retains all of the capabilities and knowledge it obtained during pre-training (no parameters are changed), and makes it significantly quicker and easier to provide the LLM with up-to-date knowledge (simply add or modify the documents in the database).
Pipeline Pilot RAG Prototype
I developed a basic RAG implementation for Pipeline Pilot component assistance as a proof-of-concept. My initial goal was to produce a model that would help me find components quickly and easily, as well as help me with both designing and debugging pipelines. Therefore, to start with, I decided to focus my efforts just on the help text that is available for every component and protocol (as well as all of their parameters) in Pipeline Pilot.
As it turns out, this proof-of-concept is actually quite helpful! The screenshot below shows how my proof-of-concept RAG demo was able to understand a relatively complex query and suggest a sensible protocol which I was able to easily implement in Pipeline Pilot.

Figure 1. Screenshot of conversation with RAG-based prototype, showing how it responds sensibly to a complex user query.
Here is a screenshot showing the Pipeline Pilot protocol it suggested, after having successfully processed my 10 SMILES strings:
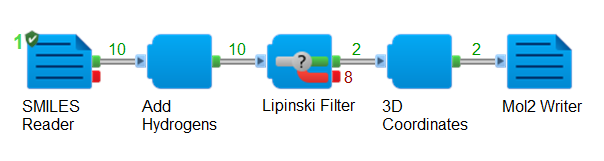
Figure 2. Pipeline Pilot protocol suggested by the RAG-based prototype after having successfully processed some data.
As a new user of Pipeline Pilot, I find asking questions this way really convenient and helpful. It has helped me and other new starters in my team to get up to speed with Pipeline Pilot more quickly.
Our Longer-Term Vision
The prototype model is already in use by teams within BIOVIA and is undergoing rapid development and improvements. Whilst in the near-term, we are focussed on improving the model’s ability to help users understand how best to leverage the components and protocols available to them, I wanted to share with you a bit more of our ambition for LLMs in the context of Pipeline Pilot.
The existing RAG model shows tantalising hints of where this work could go next; note that at the end of the output from the model it has provided a schematic of a protocol! The building of the protocol can be automated allowing an LLM assistant to help design protocols from scratch to accomplish a task provided by the user in natural language. It is also possible to provide our LLMs with the ability to run protocols (whether they have been provided by the user or designed by the LLM). This kind of LLM-based agent, with the human firmly in the loop, should allow significantly increased productivity without compromising on safety.
Conclusion
Watch this space for future updates on our LLM-based applications as we continue to innovate and enhance our tools to better serve our users. Learn more about Pipeline Pilot here.

After completing an MChem at the University of Oxford, Mark went on to undertake a PhD in the group of Professor Kenneth Shankland at the University of Reading. During his PhD, he focussed on crystal structure determination from powder diffraction data. In 2014, Mark completed a short post-doctoral research position. He applied Rietveld-based quantitative phase analysis to determine the mass fractions of crystalline and amorphous ingredients in chocolate precursors. Following this, he taught undergraduate chemistry for several years, first as a teaching fellow at the University of Reading and then as a senior lecturer in the UK Civil Service. Despite working in teaching-centric roles, he maintained an active research agenda with interests in crystallography, machine learning, and artificial intelligence. In February of 2024, he joined the Materials AI team within BIOVIA