
【第8章 複雑性設計に対応する】設計プロセスの複雑性~Process Integration & Design Optimization
ダッソー・システムズの工藤です。今回は、「設計プロセスの複雑性」についてお話します。カテゴリーの全体像については、62:複雑性設計をモデル・データ・プロセスの視点で整理する をご覧ください。
設計プロセスの複雑性(本章で解説)
What:異なる解析領域のCAEアプリケーション同士の入出力データや実行プロセスが、複雑に絡み合う複合領域や階層構造を持つ設計問題
How:設計プロセスのワークフロー化、PIDO (Process Integration & Design Optimization)
言うまでもなく、このブログのタイトルにもなっているようにシミュレーション(CAE)は設計行為の一環として使われており、CAEを実行するプロセスは、設計プロセスの中に組み込まれています。複合的なCAE性能計算の各プロセスごとにワークフローを作成し、それらの入出力ファイルを相互につなげいけば、さらに複雑な設計プロセスとなり、一つの製品全体の設計プロセスを大きなワークフローで表現できれば、自動設計が実現します。この技術を総称して、PIDO (Process Integration & Design Optimization)と呼びます。
PIDOの歴史は、私どもの製品Isightの前身であるGEの社内ツールの時代から始まるといってもいいでしょう。その誕生の時の逸話を本ブログ“10 : ソフトウエア・ロボットの誕生”に、私が初めてこの技術に出会ったときの驚きを“17 : 最適設計支援ソフトウエアの衝撃的な登場“に書いています。また、そのその究極のビジョンと実行形態が“14 : Zero Design Cycle Timeの衝撃”に示されていますので、改めてお目通しください。私がエンジニアス・ジャパンという会社で、Computer-Aided Optimization (CAO)という標語のもとで、Isight製品の販促活動をし始めた1998年~2000年頃のスライドを添付しています。20年前ですが、基本的なコンセプトは変わっておらず、むしろ大半のお客様においては、未だに実現できていないことに驚かされます。PIDOのコンセプトと技術は非常に汎用的で長期的な見通しに立ったものであることが分かります。さらにこの先何十年も基盤であり続けることは間違いありません。
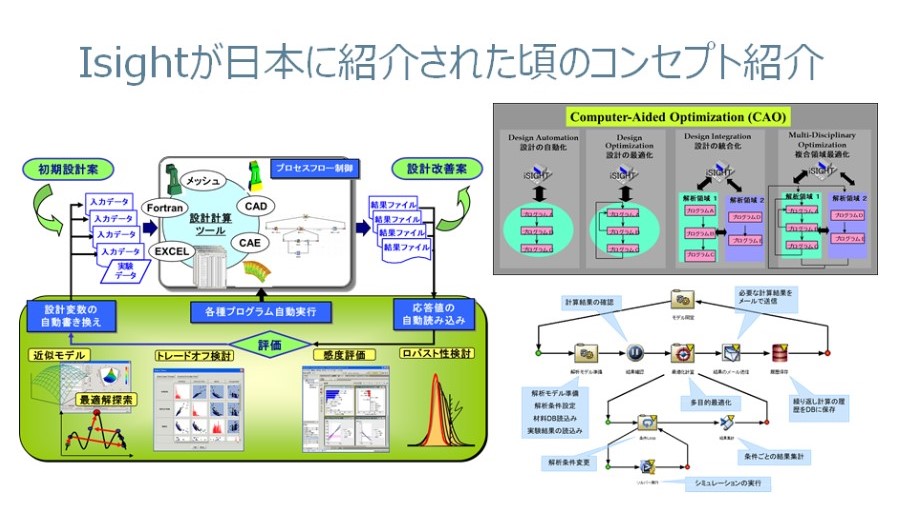
実際に、どのようなレベルまで設計プロセスのワークフロー化、自動化が進んでいるか事例はたくさんあるのですが、本ブログの中でお見せできるのは難しいので、URLを紹介してみていただくことにしましょう。下記のeBookにはたくさんのワークフローの事例が示されています。シミュレーションのタスクの多さ、階層構造の深さなど実際の設計問題に適用されているワークフローがいかに複雑であるかがわかるでしょう。適用分野は問いませんが、特に自動車開発、ジェットエンジン開発、航空機開発の領域がもっとも進んでいると言えます。
Robust Design in Less Time ~ Industrial Equipment – Turbomachinery
先ほど来ワークフローという言葉をつかっていますが、どういう順番でワークのフローが決まるかというと、実は、プロセス同士のデータ入出力の依存関係、すなわちデータフローが重要なのです。前回説明したDSMを理解していればすぐにおわかりいただけるのですが、簡単にお話しましょう。フローAとフローBがあるとします。AとBはお互いにその入出力データを参照することなく独立であれば、二つのフローは平行に実行することができます。例えば、振動問題と強度計算の問題は依存しないので独立のフローとなります。一方、AのアウトプットをBのフローが入力として使うとしましょう。例えば、流体圧を受けて構造が変形する問題の場合は、流体計算のフローAを先に計算し、その圧力場のファイルを構造解析のフローBに渡す必要があります。これにより、流体計算を先に実行し、その結果をINPUTとして構造解析を次に実行するというフローの順番が決まります。順番を逆にすることはできないので、このデータ・フローの依存関係を繋いでいくことで、複雑なフローがほぼ一意的に出来上っていくのです。そうしてできた、実際のワークフローは実に複雑に見えますが、データ・フローの見地から合理的なフローになっているのです。ワークフローは、データフローを構成することで構築できると覚えておきましょう。この理解が、ワークフローを自動的に構築するというアイデアにつながり、後の記事で紹介するテーマとなります。
【DASSAULT SYSTEMES 工藤啓治】

工藤はCAE分野で39年の経験を持つエキスパートとして、CAE開発・販売、HPC活用・マーケティング、最適設計・ロバスト設計市場開拓などを経験し、現在はシミュレーションを活用した設計業務改革コンサルと自身のノウハウ形式知化に取り組んでいます。