
Traditionally, relational databases were designed for scale-up architectures. Supporting more clients or higher throughput required an upgrade to a larger server. Until recently, this meant that implementing a read & write scale-out architecture either required a NoSQL database and abandoning traditional relational database benefits, or relying on sharding and explicit replication. There were no solutions that could scale-out and still provide complete ACID (Atomicity, Consistency, Isolation, and Durability) -compliant semantics. This tension is what inspired the NewSQL movement and ultimately led to today’s modern distributed SQL databases.

NuoDB is a distributed SQL database designed with distributed application deployment challenges in mind. It’s a full SQL solution that provides all the properties of ACID-compliant transactions and standard relational SQL language support. It’s also designed from the start as a distributed system that scales the way a cloud service has to scale, providing high availability and resiliency with no single points of failure. Different from traditional shared-disk or shared nothing architectures, NuoDB’s patented database presents a new kind of peer-to-peer, on-demand independence that yields high availability, low-latency, and a deployment model that is easy to manage.
This article highlights the key concepts and architectural differences that set NuoDB apart from traditional relational databases and even other distributed SQL databases.
The NuoDB Architecture
Multiple Independent Services
NuoDB splits the traditional monolithic database process into two independent services: a transactional processing service and a storage management service. Each service can be scaled independently. It also has an administration component. This section focuses on the transactional and storage processing services tiers that support application database activity.
Splitting the transactional and storage processing services is key to making a relational system scale. Traditionally, an SQL database is designed to synchronize an on-disk representation of data with an in-memory structure (often based on a B-tree data-structure). This tight coupling of processing and storage management results in a process that is hard to scale out. Separating these services allows for an architecture that can scale out without being as sensitive to disk throughput (as seen in shared-disk architectures) or requiring explicit sharding (as seen in shared-nothing architectures).
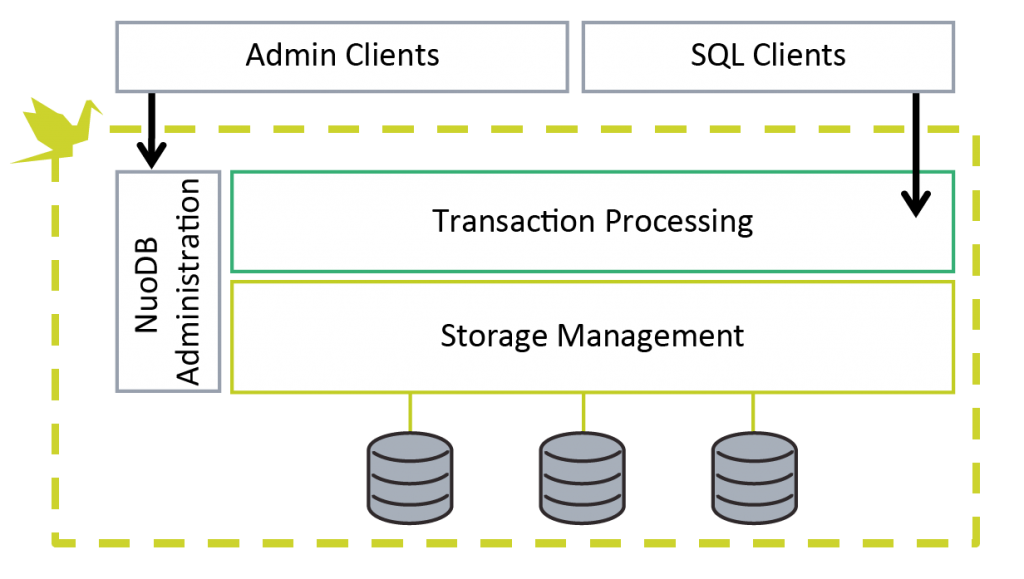
In NuoDB, durability is separated from transactional processing. These services are scaled separately and handle failure independently. Because of this, transactional throughput can be increased with no impact on where or how data is being stored. Similarly, data can be stored in multiple locations with no effect on the application model. Not only is this key to making a database scale, it enables NuoDB to scale on-demand and implement powerful automation models.
The transaction service is responsible for maintaining Atomicity, Consistency, and Isolation in running transactions. It has no visibility into how data is being made durable. It is a purely in-memory tier, so it’s efficient as it has no connection to durability. The transaction service is an always-active, always consistent, on-demand cache.
The storage management service ensures Durability. It’s responsible for making data durable on commit and providing access to data when there’s a miss in the transactional cache. It does this through a set of peer-to-peer coordination messages.
The two services discussed above consist of processes running across an arbitrary number of hosts. NuoDB defines these services by running a single executable in one of two modes: as a Transaction Engine (TE) or a Storage Manager (SM). All processes are peers, with no single coordinator or point of failure and with no special configuration required at any of the hosts. Because there is only one executable, all peers know how to coordinate even when playing separate roles. We refer to TEs and SMs as Engines.
TEs accept SQL client connections, parsing and running SQL queries against cached data. All processes (SMs and TEs) communicate with each other over a simple peer-to-peer coordination protocol. When a TE takes a miss on its local cache, it can get the data it needs from any of its peers (either another TE that has the data in-cache or an SM that has access to the durable store).
This simple, flexible model makes bootstrapping, on-demand scale-out, and live migration very easy. Starting and then scaling a database is simply a matter of choosing how many processes to run, where, and in which roles. The minimum ACID NuoDB database consists of two processes, one TE and one SM, running on the same host.
Starting with this minimal database, running a second TE on a second host doubles transactional throughput and provides transactional redundancy in the event of failure. When the new TE starts up, it mutually authenticates with the running processes, populates a few root objects in its cache, and then is available to take on transactional load. The whole process takes less than 100ms on typical systems. The two TEs have the same capabilities and are both active participants in the database.
Similarly, maintaining multiple, independent, durable copies of a database is done by starting more than one SM. A new SM can be started at any point, and will automatically synchronize with the running database before taking on an active role. Once synchronized, the new SM will maintain an active, consistent archive of the complete database.
Atoms: Internal Object Structure
The front-end of the transactional tier accepts SQL requests. Beneath that layer, all data is stored in and managed through objects called Atoms. Atoms are self coordinating objects that represent specific types of information (such as data, indexes or schemas). All data associated with a database, including the internal metadata, is represented through an Atom.
The rules of Atomicity, Consistency, and Isolation are applied to Atom interaction with no specific knowledge that the Atom contains SQL structure. The front-end of a TE is responsible for mapping SQL content to the associated Atoms, and likewise part of the optimizer’s responsibility is to understand this mapping and which Atoms are most immediately available.
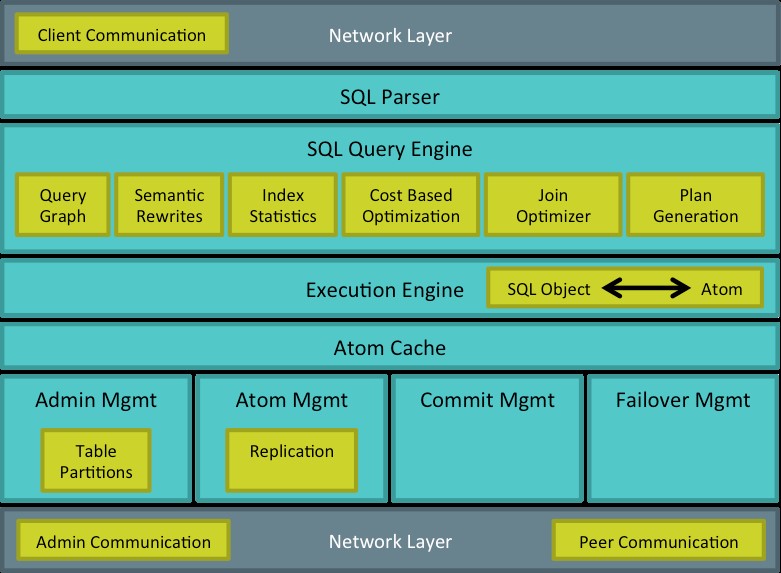
Atoms are chunks of the database that can range in size, unlike pages or other traditional on-disk structures that are fixed size. Atoms are also self-replicating, ensuring that an Atom’s state is consistent across Engines. The size of an Atom is chosen to help maximize efficiency of communication, minimize the number of objects tracked in-cache, and simplify the complexity of tracking changes.
Only required objects are pulled into a cache. Once an object is no longer needed, it can be dropped from the cache. A TE can request an object it needs from another TE cache any time. If a TE doesn’t have a given Atom in its cache, it doesn’t participate in cache update protocols for that Atom.
Data Durability
Abstracting all data into Atoms is done in part to simplify the durability model. Each Atom is stored as key-value pair file. By design, durability can be done with any file system that supports a CRUD interface and can hold a full archive of the database.
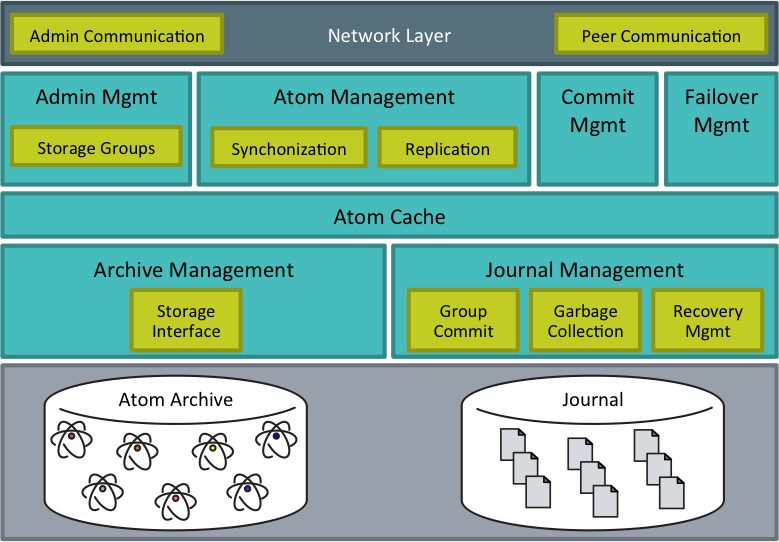
In addition to tracking the canonical database state in its archive, SMs also maintain a journal of all updates. Because NuoDB uses MVCC, the journal is simply an append-only set of diffs, which in practice are quite small. Writing to and replaying from the journal is efficient.
Management Tier
Along with the two database services is a management service. As with databases, the management service is a collection of peer processes. These processes are called Brokers, and one runs on every host where a database could be active. Starting a management service on a host is a provisioning step; it makes the host available to run database processes and visible to the management environment. This collection of provisioned hosts is called a Management Domain.
A Domain is a management boundary. It defines the pool of resources available to run databases and the set of users with permission to manage those resources. In traditional terms, a DBA focuses on a given database and a systems administrator works at the management domain level.
Each Broker is manages a set of Engines. For physical server deployments, this is typically the Engines running on the same local host. A Broker is responsible for Engine process management (start/stop), monitoring, and configuration management. A Broker also has global view of all Brokers in the Domain, and therefore all processes, databases, and events that are useful from a monitoring point of view.
All Brokers have the same view of the Domain and the same management capabilities. So, like the Engines, there is no single point of failure at the management level as long as multiple Brokers are deployed. Provisioning a new host for a Domain is done by starting a new Broker peered to one of the existing Brokers.
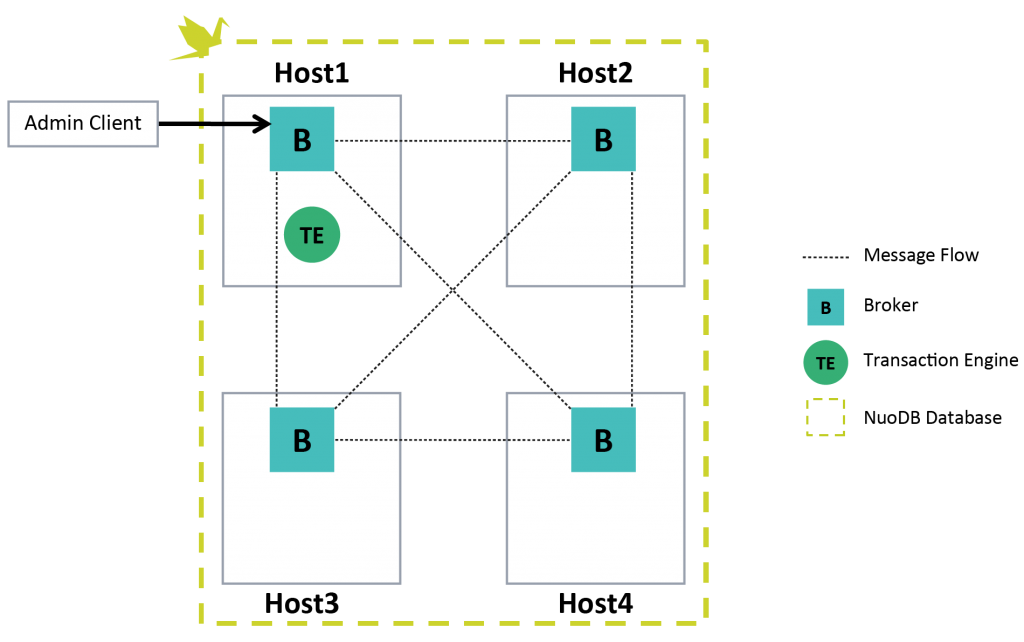
When an SQL client wants to communicate with a TE, it starts by connecting to a Broker. The Broker tells the client which TE to establish a connection with. This connection brokering is one of the key roles of a Broker, and means that a Broker is also a load-balancing point. Load-balancing policies are pluggable and can be implemented to support optimizations around key factors, like resource utilization or locality.
Just as an SQL programmer addresses a NuoDB database as a single, logical entity even though it’s distributed across many processes, a systems administrator addresses a Domain as a single, logical point of management. This is done through any of the Brokers. They provide a single place to connect to a Domain, manage and monitor databases, and ensure that the system is running as expected.
Conclusion
As software development organizations are moving to a cloud-deployment model, a new database architecture is needed. This article has covered the key architectural elements of NuoDB – the cloud native distributed SQL database.

Ross Shaull is the NuoDB Platform & Orchestration Systems Architecture Director. Ross has over 15 years of database architecture and design experience and is one of the original NuoDB design architects dating back to NuoDB version 1. Ross earned his Ph.D. in Computer Science from Brandeis University.