
안녕하세요. 다쏘시스템 SIMULIA 브랜드팀 입니다.
이 번 포스팅에서는Abaqus 결과 파일인 ODB 내용을 외부에서 자동화 처리를 할 수 있는Abaqus Scripting Interface(ASI)에 대해 설명 드리겠습니다.
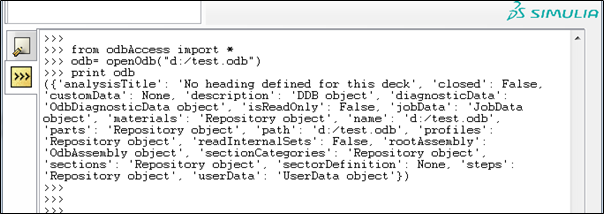
Abaqus Scripting Interface에 의한 ODB의 결과처리 자동화는 Abaqus /Viewer CLI(Command Line Interface) 또는 외부 명령어 창(Abaqus python)에서 python script 명령어를 통해 접근이 가능합니다. (그림 1,2)
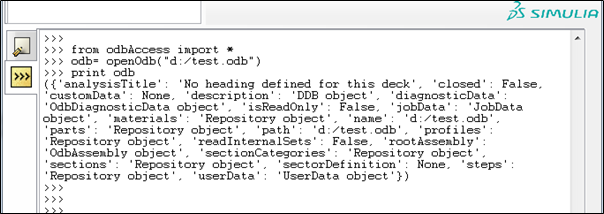
그림 1. Abaqus /Viewer CLI(Command Line Interface)를 통한 ODB 처리
그림 2. Abaqus Python Command창을 통한 ODB 처리
Abaqus /Viewer 환경에서 ODB의 결과 처리 자동화는 plug-in으로 사용하거나, 결과 이미지 캡쳐 및 그래프 출력과 연계하여 구현할 수 있습니다. Abaqus python 명령어 창에서 ODB를 처리하는 경우는, Abaqus /Viewer의 라이선스 없이 ODB 결과 처리를 할 수 있지만, 다양한Abaqus /Viewer후처리 기능을 활용할 수 없습니다.
그럼, 먼저 ODB 결과 파일에 어떻게 데이터가 저장되어 있는지 데이터 구조를 살펴 보겠습니다.
ODB 데이터 모델 ODB의 데이터 내용은 크게 model data와 results data로 나눌 수 있습니다. Model data 영역은 Abaqus 해석 모델의 주요 element/node sets, instances, sections 및 material의 정보를 저장하고 있습니다.(그림 3) Results data는 field output과 history output 영역으로 나뉘는데, Abaqus /Viewer에서 처리되는 UI와 동일한 형태로 데이터 접근이 가능합니다. 예를 들어 특정 node set의 변위 결과를 추출하려면, 순차적으로 해당하는 step, frame을 지정하고 변위type의 field output 항목을 특정 node set에 대해 출력해야 합니다.
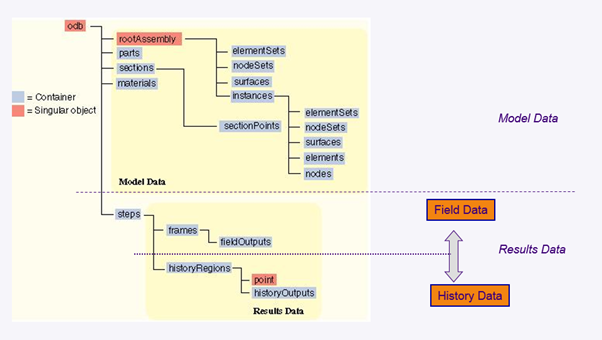
그림 3. ODB 데이터 구조
ODB의 fieldoutput 결과를 추출하기 위한 단계별 절차와 유틸리티는 다음과 같습니다.
1) ODB open ASI를 통해 ODB를 접근하는 방법은 ODB 데이터 모델의 계층적인 구조의 각 object path를 통해 접근하는 것입니다. 이를 위해 제일 먼저 필요한 module은”odbAcess” 이고, openOdb 함수를 통해 ODB를 열 수 있습니다. (그림 4)

그림 4. ODB를 접근하기 위한 python module 과 함수
2) ODB step 선택 Open한 ODB에서 result data를 처리하기 위한 첫 번째 object path는 steps object입니다. Steps object는 step 이름을 key값으로 저장하고 있는 repository data type입니다. Python의 dictionary와 유사한 형태로 step 이름을 key로 입력하여 접근할 수 있습니다. Object path는 “.”로 구분되며, ODB 데이터 모델 구조에 따라 계층적으로 표현됩니다. 예를 들어 “Crush”란 이름의 step name을 갖는 steps의 object path는 “odb.steps[‘Crsuh’]” 입니다. 여러 step으로 구성된 경우는 각 step 이름을 key로 입력하거나, steps.values() 함수의 리턴값의 index를 지정하여 object path를 표현할 수 있습니다. ( [-1] index는 마지막을 의미 ) Abaqus CLI환경에서는 tab을 이용하여 순차적으로 key 값을 자동 입력할 수 있습니다. Steps object는 해석 increments를 지정하는 frames object의 상위 object path로 사용됩니다.
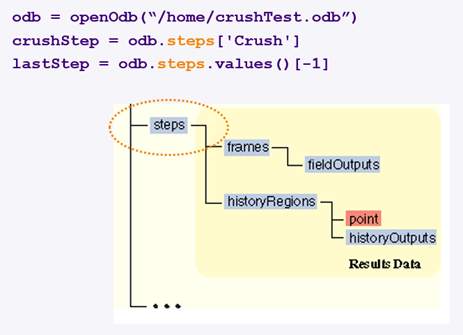
그림 5. Steps object구조
3) ODB frame 선택 frames object는 index형태로 해석 increment를 선택하여 object path로 나타낼 수 있습니다. ( index는 0부터 시작하고, -1은 마지막을 의미합니다. )
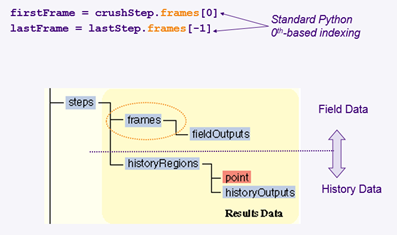
그림 6. Frames object구조
4) ODB fieldOutputs 선택 fieldOutputs object는 Abaqus output request variable을 key값으로 저장하고 있는 repository data type입니다. Python의 dictionary와 유사한 형태로 result variable 이름을 key로 입력하여 접근할 수 있습니다. 예를 들어 ‘Crush’ step을 선택하고, 마지막 increment의 stress결과를 접근하기 위한 object path는 그림7과 같이 나타낼 수 있습니다.

그림 7. Stress 결과를 접근하기 위한 fieldOutputs object path
fieldOutputs object의 stress 결과를 접근하기 위해서는 ‘S’ key를 입력하여 object path를 확인하고 여러 개의 결과가 array 형태로 저장되어 있는 values 멤버변수의 index를 통해 field value object를 사용할 수 있습니다.(그림 8) 해당되는 stress tensor 결과를 출력하기 위해서는 선택된field value object path와 data 멤버변수를 통해 S11,S22,S33 and S12 값을 확인할 수 있습니다. ( 예, fieldOutputs[‘S’].values[0] -> 첫 번째 field value object fieldOutputs[‘S’].values[0].data -> stress tensor 결과 )
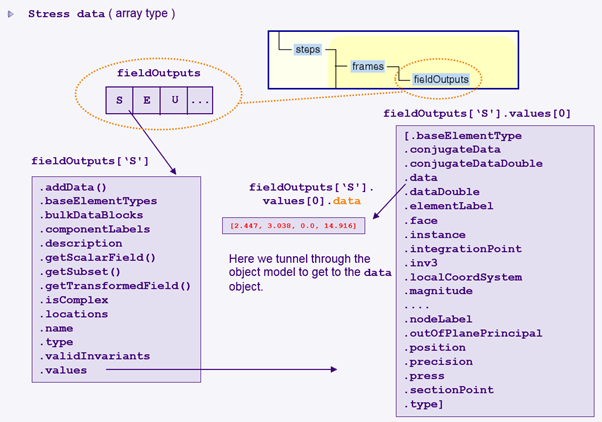
그림 8. Stress 결과 출력 ( field value array 선택 및 data 멤버변수 지정 필요 )
4) ODB fieldOutputs filter 방법 결과 출력 시, 모든 결과를 한번에 출력하는 것이 아니라 특정 position(NODAL, INTEGRATION_POINT,CENTROID 등), region( node set, element set) 및 element type에 대해 filter출력을 할 수 있습니다. 이를 위해서getSubset() 함수를 이용할 수 있는데, fieldOutputs object path를 받아 사용할 수 있습니다. (그림 9)
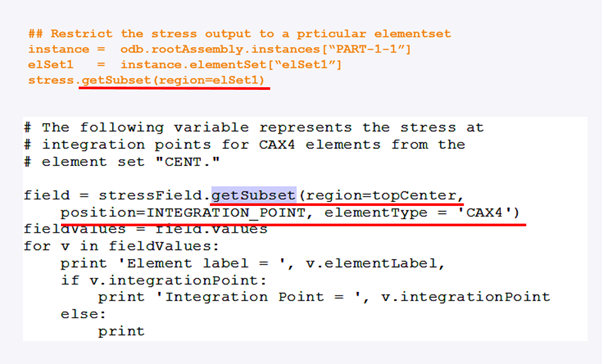
그림 9. getSubset 함수를 이용한 결과데이터 filter
지금까지ODB fieldoutput 결과를 추출하기 위한 주요 절차와 object path에 대해 살펴 보았습니다.
그럼, 간단한 예제를 가지고 확인해 보겠습니다.
예제) 특정 node set의 변위 결과 출력 여러 개의 step으로 진행된 해석결과 ODB에서 ”Step-1” step, 마지막 increment에서 PUNCH node set의 변위결과를 출력하는 예제입니다. (그림 10)
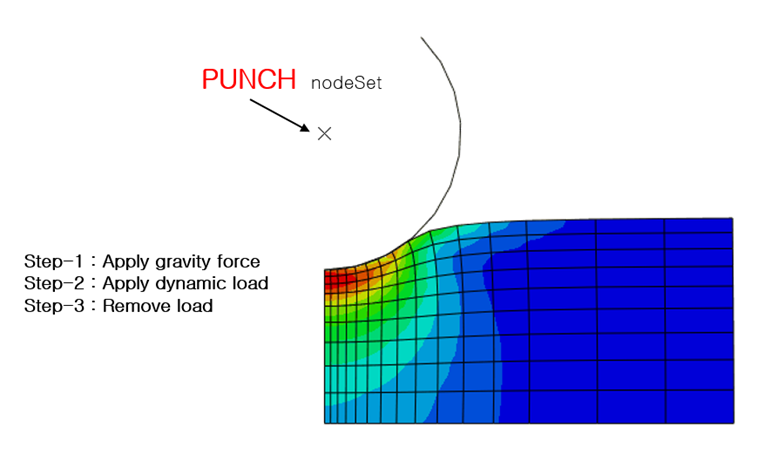
그림 10. Multi-step으로 해석된 ODB 파일 ( PUNCH node set 포함 )
먼저, odbAccess 모듈을 import 한 뒤, openOdb 함수를 이용해 “indentfoam_std_visco_2.odb” 파일을 열고 odb 변수에 object를 반환하고 계층구조로 데이터를 접근합니다. “Step-1”의 마지막increment를 선택하기 위해, “Step-1” 문자열로 steps object의 key 값을 입력하고, 마지막 increment는 -1 index를 이용해 지정합니다. 변위 결과의 fieldoutputs 출력을 위해서는 ‘U’ key 값을 입력하여 object path를 확인합니다. ( 변위결과 object path : odb.steps[‘Step-1’].freames[-1].fieldOutputs[‘U’] ) 모든 변위 결과 중, ‘PUNCH’ node set에 대한 결과만 출력하기 위해 getSubset 함수를 이용해야 하는데, region은 반드시 node set object path 형태로 입력이 필요합니다. ( node set object path : odb.rootAssembly.instances[‘PART-1-1’].nodeSets[‘PUNCH’] ) getSubset으로 필터링 된 결과는 values 변수로 반환되고, 개수가 여러 개인 경우 for 문 형식으로 각 node의 position, type, nodeLabel 및 data를 출력할 수 있습니다. (그림 11)

그림 11. 특정 node set 변위 결과 출력을 위한 python script (printNodeSet.py)
맺음말 이 번 포스팅에서 Abaqus ODB 내용을 python script로 확인할 수 있는 방법에 대해 살펴보았습니다. ODB 파일은 복잡하지 않은 데이터 구조 때문에 다양한 결과가 쉽게 추출 될 수 있습니다. 하지만 데이터가 repository 형태로 한 번에 추출되기 때문에, 이를 구분할 수 있는 데이터 처리방법이 필요합니다. Getsubset filtering 함수를 사용하여 데이터 set를 축소하거나, python script의 다양한 변수 처리 방법을 이용한다면 유연한 결과처리를 할 수 있습니다. 추가 문의사항이 있으시면, 다쏘시스템코리아 시물리아 기술지원팀(02-3270-8541)으로 연락 부탁 드립니다.
ndentfoam_std_visco_2.inp
시뮬리아 아바쿠스 SIMULIA ABAQUS